|
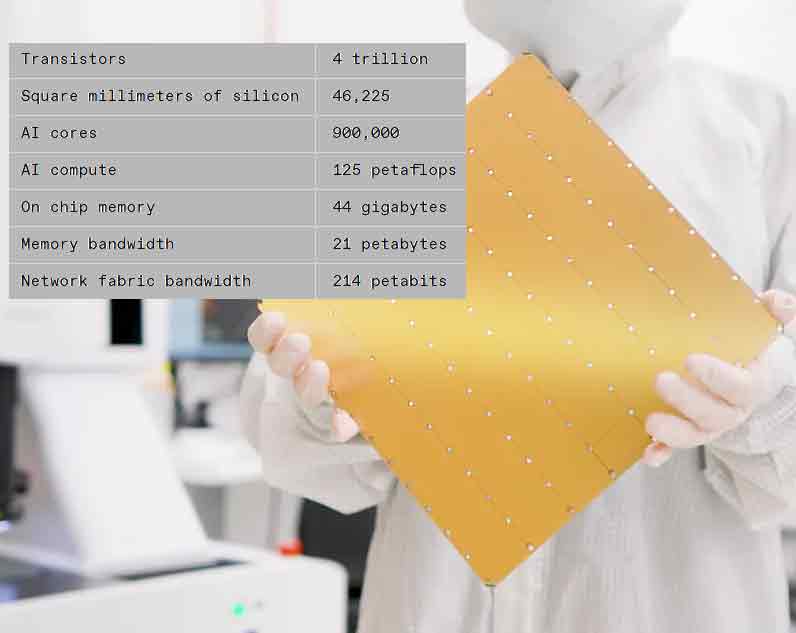
【产通社,3月15日讯】美国AI超级计算机公司Cerebras表示,其下一代waferscale AI芯片的性能比上一代产品提高一倍,而消耗相同的功率。晶圆级引擎3(WSE-3)包含4万亿个晶体管,由于使用了更新的芯片制造技术,比上一代产品增加了50%以上。该公司表示,将在新一代AI计算机中使用WSE-3,这些计算机目前安装在达拉斯的一个数据中心,形成一台能够进行8亿次浮点运算的超级计算机。
该公司表示,CS-3可以训练多达24万亿个参数的神经网络模型,是当今最大LLMs的10倍以上。公司已经与高通达成了一项联合开发协议,旨在将AI推理的性价比提高10倍。
有了WSE-3,Cerebras可以继续生产世界上最大的单芯片。该芯片呈正方形,边长215毫米,使用了几乎整个300毫米的硅晶圆来制造一个芯片。芯片制造设备通常仅限于生产不超过约800平方毫米的硅片。芯片制造商已经开始通过使用3D集成和其他先进封装技术来组合多个芯片,从而摆脱这一限制。但即使在这些系统中,晶体管数量也有数百亿个。
像往常一样,如此大的芯片伴随着一些令人兴奋的最高级。
你可以在WSE芯片的继承中看到摩尔定律的影响。第一个于2019年首次亮相,使用台积电的16纳米技术制造。对于2021年抵达的WSE-2,Cerebras转向了台积电的7纳米工艺。WSE-3是用这家晶圆巨头的5纳米技术制造的。
自第一个超大规模芯片问世以来,晶体管数量增加了两倍多。同时,用途也发生了变化。例如,芯片上AI核心的数量明显持平,内存和内部带宽也是如此。尽管如此,每秒浮点运算次数的性能提升超过了所有其他指标。
围绕新AI芯片CS-3构建的计算机旨在训练新一代巨型大型语言模型,比OpenAI的GPT-4和谷歌的Gemini大10倍。该公司表示,CS-3可以训练多达24万亿个参数的神经网络模型,是当今最大LLMs的10倍以上,而无需其他计算机所需的一套软件技巧。根据Cerebras的说法,这意味着在CS-3上训练一个1万亿参数模型所需的软件与在GPU上训练一个10亿参数模型一样简单。
可以组合多达2048个系统,这种配置将在一天内从头开始训练流行的LLM Llama 70B。不过,该公司表示,目前还没有那么大的项目。
Cerebras CEO Andrew Feldman表示,神经网络模型的执行是AI应用的天花板。Cerebras估计,如果地球上每个人都使用ChatGPT,每年将花费1万亿美元――更不用说大量的化石燃料能源了。
Cerebras和高通建立了合作伙伴关系,目标是将推理成本降低10倍。他们的解决方案将涉及应用神经网络技术,如权重数据压缩和稀疏性――删除不必要的连接。这样,经过大脑训练的网络将在高通的新推理芯片AI 100 Ultra上高效运行。(来源:IEEE;编译:镨元素)
|





